Fragestellung
Eine Person fühlt sich gerade krank und macht einen Corona-Schnelltest. Leider fällt der Test positiv aus.
Ein positiver Schnelltest
Fragestellung
Wie hoch ist die Wahrscheinlichkeit, dass ein Mensch mit positivem Corona-Test wirklich erkrankt ist? Wie hoch ist die Wahrscheinlichkeit, dass ein Mensch mit negativem Corona-Test wirklich gesund ist?
Der Test ist zwar positiv, aber wie sicher kann sich die Person sein, dass sie wirklich an Corona erkrankt ist, d.h. wie sicher kann sie sich sein, dass das Testergebnis korrekt ist? Die gleiche Frage könnte man sich auch stellen, wenn der Test negativ wäre: Wie sicher ist es in diesem Fall, dass die Person wirklich nicht an Corona erkrankt ist?
Als erstes sehen wir uns den Beipackzettel des Schnelltests in der Hoffnung an, dass wir dort Antworten auf unsere Fragen finden.

Der Beipackzettel eines handelsüblichen Covid-19-Schnelltests
Konfusionsmatrix des Schnelltests
| Person krank | Person gesund | Gesamt | |
|---|---|---|---|
| Test positiv | 139 | 3 | 142 |
| Test negativ | 13 | 462 | 475 |
| Gesamt | 152 | 465 | 617 |
Versuchen wir, die Informationen zu entschlüsseln. Offenbar wurde eine Studie durchgeführt, in der Personen Proben entnommen wurden. Diese wurden einem RT-PCR-Test und einem Schnelltest der Marke CLUNGENE per Nasenabstrich (nasal swab) unterzogen und für jede Person wurden die Ergebnisse der beiden Tests miteinander verglichen.
In dieser Studie sind wir nur an der Genauigkeit des Schnelltests interessiert. Dazu nehmen wir an, dass das Ergebnis des RT-PCR-Tests exakt ist und wir damit wissen, ob eine Person an Covid-19 erkrankt ist oder nicht. Wir überprüfen dann, ob der Schnelltest den Krankheitszustand der Personen richtig erkennt oder nicht. Statt Schnelltest schreiben wir ab hier nur kurz Test.
Werten wir das Ergebnis eines solchen Tests aus, können wir zunächst feststellen, dass wir es mit vier Möglichkeiten zu tun haben:
- Die Person ist krank und der Test ist positiv.
- Die Person ist krank und der Test ist negativ.
- Die Person ist gesund und der Test ist positiv.
- Die Person ist gesund und der Test ist negativ.
Man kann das übersichtlich als Tabelle darstellen:
| Person krank | Person gesund | |
|---|---|---|
| Test positiv | richtig positiv | falsch positiv |
| Test negativ | falsch negativ | richtig negativ |
Diese Tabellendarstellung wird Wahrheitsmatrix oder auch Konfusionsmatrix genannt.
Unter der Konfusionsmatrix im Beipackzettel finden wir noch zwei Prozentangaben: PPA und NPA. Diese wurden aus den Werten in der Tabelle berechnet und sind Gütemaße für medizinische Tests:
PPA bedeutet Positive Percent Agreement oder auch Richtig-Positiv-Rate, bzw. Sensitivität (Sensitivity). Der Wert gibt an, wie viele Prozent von nachweislich positiven Covid-Fällen vom Test richtig als positiv erkannt werden. Bei unserem Test sind es im Mittel 91.4%.
NPA bedeutet Negative Percent Agreement oder auch Richtig-Negativ-Rate, bzw. Spezifität (Specificity). Der Wert gibt an, wie viele Prozent von nachweislich negativen Covid-Fällen vom Test richtig als negativ erkannt werden. Bei unserem Test sind es im Mittel 99.4%.
Warum beantworten Testgenauigkeit, Sensitivität und Spezifität nicht unsere eigentliche Fragestellung, die wir in der Zusammenfassung rechts oben sehen? Das werden wir uns auf der folgenden Seite anschauen.
Analyse
Zur Formalisierung des Problems stellen wir das Vorgehen in der Studie als Baumdiagramm dar, was uns später bei der Beantwortung der eigentlich Fragestellung helfen wird. Wir wissen, wer gesund und wer krank ist und überprüfen für diese Gruppen von Personen jeweils, wie der Test ausfällt:
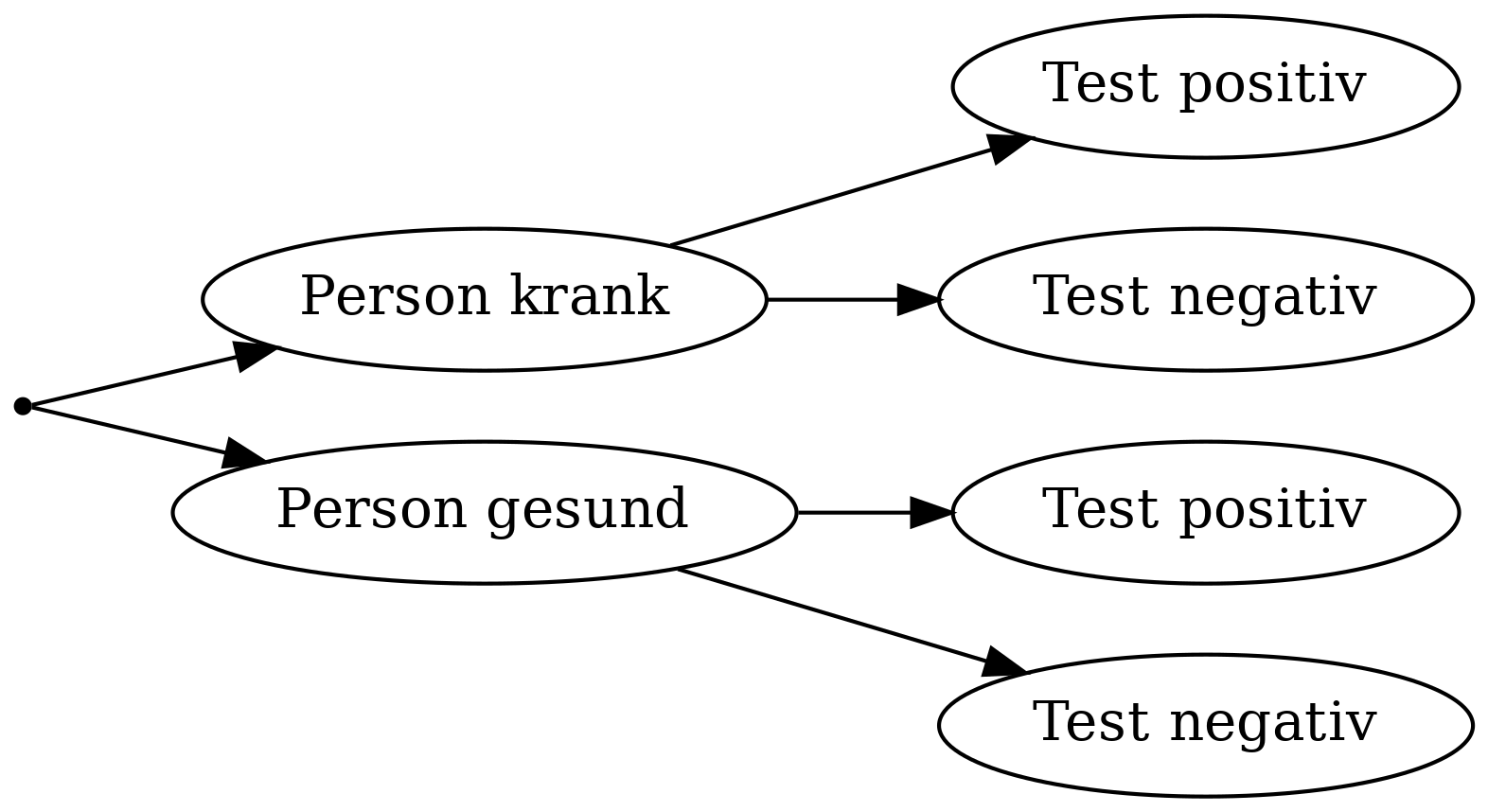
Baumdiagramm mit Ereignissen
Damit wir später gut rechnen können, definieren wir zunächst zwei Ereignisse und deren Negation. Diese entsprechen den oben genannten Möglichkeiten:
- \(K\):Person krank
- \(\overline K\): Person gesund
- \(T\): Test positiv
- \(\overline T\): Test negativ
Definition der Ereignisse
- \(K\):Person krank und \(\overline K\): Person gesund
- \(T\): Test positiv und \(\overline T\): Test negativ
Diese Ereignisse können wir in ein Baumdiagramm übertragen, zusammen mit den dazugehörigen Wahrscheinlichkeiten \(P\):
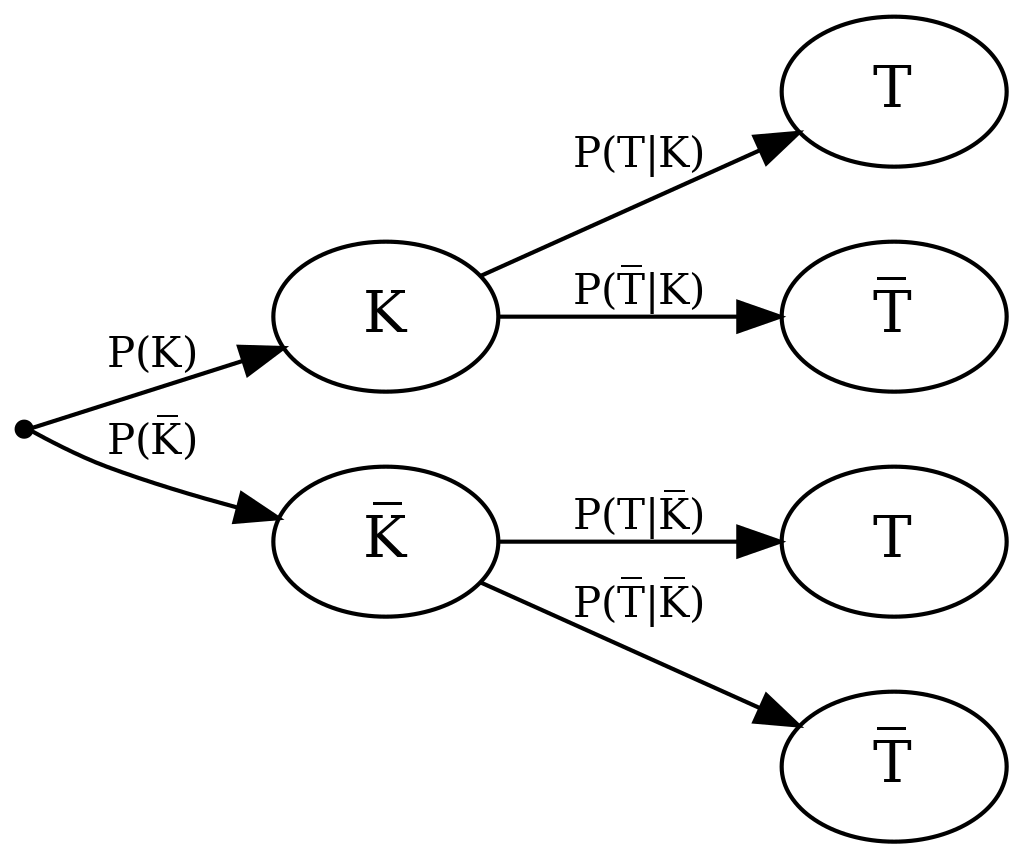
Baumdiagramm mit Ereignissen und deren Wahrscheinlichkeiten
Wie in der Frage eingangs formuliert, möchten wir wissen, wie hoch die Wahrscheinlichkeit ist, dass eine Person tatsächlich krank ist, wenn der Test positiv ausfällt. Das lässt sich mithilfe der oben definierten Ereignisse als bedingte Wahrscheinlichkeit formulieren – die Wahrscheinlichkeit, dass eine Person krank ist, gegeben dass der Test positiv ist: \(P(K \mid T)\). Diese Wahrscheinlichkeit wird auch positiver Vorhersagewert genannt, aber sie taucht im obigen Baumdiagramm nicht auf. Dort sind die Ereignisse K und T vertauscht wie in \(P(T \mid K)\).
\(P(T \mid K)\) wird Sensitivität genannt und ist ein Gütemaß für einen Test, wie wir im Beipackzettel schon gesehen haben. Die Sensitivität gibt an, wie hoch die Wahrscheinlichkeit ist, dass der Test ein positives Ergebnis anzeigt für eine tatsächlich erkrankte Person und wird daher auch Richtig-positiv-Rate genannt.
Um nun den eigentlich gesuchten positiven Vorhersagewert, also die bedingte Wahrscheinlichkeit \(P(K \mid T)\) zu berechnen, können wir den Satz von Bayes benutzen:
Satz von Bayes
\[ P(K \mid T) = \frac{P(T \mid K) P(K)}{P(T)}. \]
\[ P(K \mid T) = \frac{P(T \mid K) P(K)}{P(T)}. \]
Was wir also brauchen, um \(P(K \mid T)\) zu berechnen, sind drei Wahrscheinlichkeiten: \(P(K)\), \(P(T \mid K)\) und \(P(T)\).
Definition der bedingten Wahrscheinlichkeiten
\(P(K \mid T)\) – Wahrscheinlichkeit, dass eine Person tatsächlich krank ist, unter der Bedingung dass der Test positiv ist
\(P(K)\) gibt an, wie hoch generell die Wahrscheinlichkeit ist, zu diesem Zeitpunkt an Corona erkrankt zu sein – ganz unabhängig von einem Testergebnis. Diesen Wert nennt man auch Prävalenz. Genau können wir diese Wahrscheinlichkeit niemals wissen, aber wir können einen Schätzwert nehmen, der dem Anteil der aktuell an Corona infizierten Menschen in Deutschland entspricht. Setzen wir zunächst \(P(K) = 0.2\%\). Das ist in etwa die Prävalenz bei der ersten Coronawelle im Frühjahr 2020 in Deutschland.
Man könnte auch auf die Idee kommen, \(P(K)\) aus der Studie im Beipackzettel abzulesen, doch das ist in den meisten Fällen nicht sinnvoll: die Studie, die zu den Ergebnissen im Beipackzettel geführt hat, untersucht ja gerade wie gut der Test bei kranken Personen funktioniert, daher wurden gezielt Menschen mit und ohne nachweislicher Covid-Infektion getestet, so dass hier nicht von einem Querschnitt der Bevölkerung gesprochen werden kann.
Definition der bedingten Wahrscheinlichkeiten
\(P(T \mid K)\) – Wahrscheinlichkeit, dass ein Test ein positives Ergebnis anzeigt, unter der Bedingung dass die Person tatsächlich erkrankt ist (Sensitivität)
Die Wahrscheinlichkeit \(P(T \mid K)\) ist im Beipackzettel als Sensitivität schon angegeben.
Schließlich fehlt noch \(P(T)\): die Wahrscheinlichkeit dafür, dass eine Person – egal ob krank oder gesund – bei einem Test ein positives Ergebnis erhält. Hier hilft uns das Gesetz der totalen Wahrscheinlichkeit, das es uns erlaubt, die Wahrscheinlichkeiten für die beiden Möglichkeiten, die zu positiven Tests führen (Person krank und Person gesund), zu addieren, da sie sich gegenseitig ausschließen:
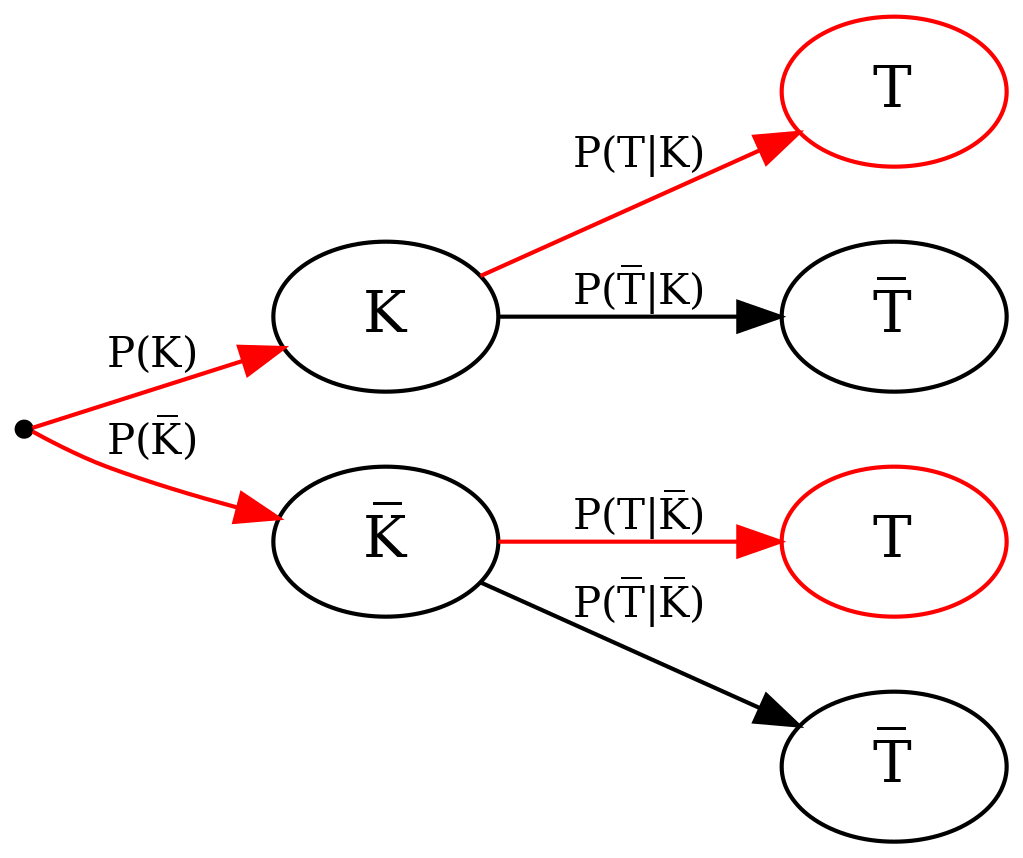
Baumdiagramm mit beiden Möglichkeiten, die zu positiven Tests führen
Somit erhalten wir
\[ P(T) = P(T \mid K) P(K) + P(T \mid \overline K) P(\overline K), \]
und damit
\[ P(K \mid T) = \frac{P(T \mid K) P(K)}{P(T)} = \frac{P(T \mid K) P(K)}{P(T \mid K) P(K) + P(T \mid \overline K) P(\overline K)}. \]
Das bringt uns allerdings zwei neue Probleme ein: Wir brauchen \(P(T \mid \overline K)\) und \(P(\overline K)\). Beides können wir zum Glück über die Wahrscheinlichkeit für komplementäre Ereignisse berechnen. Damit ist \(P(\overline K)\) (die generelle Wahrscheinlichkeit nicht krank zu sein) leicht zu errechnen, denn \(P(K)\) (die generelle Wahrscheinlichkeit krank zu sein, geschätzt mittels Prävalenz) kennen wir schon: \(P(\overline K) = 100\% - P(K) = 99.8\%\).
Fehlt zu guter letzt noch \(P(T \mid \overline K)\): Die Wahrscheinlichkeit ein positives Testergebnis zu haben, wenn man eigentlich gesund ist (ein falsch-positives Ergebnis). Hier hilft uns ein weiteres Gütemaß für Tests weiter: die Spezifität, auch Richtig-negativ Rate genannt. Sie gibt uns die Wahrscheinlichkeit an, dass eine Person ein negatives Testergebnis erhält, wenn sie tatsächlich gesund ist, also \(P(\overline T | \overline K)\). Auch die Spezifität wird oft im Beipackzettel von Schnelltests abgedruckt, wie wir schon gesehen haben. Wie wir im Baumdiagramm erkennen, ist \(P(\overline T | \overline K)\) komplementär zu \(P(T | \overline K)\) und damit gilt \(P(T | \overline K) = 100\% - P(\overline T | \overline K)\).
Satz von Bayes
\[\begin{align} P(K \mid T) &= \frac{P(T \mid K) P(K)}{P(T)} \\ &= \frac{P(T \mid K) P(K)}{P(T \mid K) P(K) + P(T \mid \overline K) P(\overline K)}. \end{align}\]
Definition der bedingten Wahrscheinlichkeiten
\(P(\overline T \mid \overline K)\) – Wahrscheinlichkeit, dass ein Test ein negatives Ergebnis anzeigt, unter der Bedingung dass die Person tatsächlich gesund ist (Spezifität)
Berechnung
Um beispielhaft zu berechnen, wie hoch die Wahrscheinlichkeit ist, dass eine Person tatsächlich krank ist, wenn sie ein positives Testergebnis von unserem betrachteten Schnelltest erhält, notieren wir noch mal die Sensitivität und Spezifität aus dem Beipackzettel:
- Sensitivität: \(P(T \mid K) = 91.4\%\)
- Spezifität: \(P(\overline T \mid \overline K) = 99.4\%\)
Für die Prävalenz hatten wir \(P(K) = 0.2\%\) angenommen.
Damit können wir die Werte in die Formel einsetzen und erhalten:
\[\begin{align} P(K \mid T) &= \frac{P(T \mid K) P(K)}{P(T \mid K) P(K) + P(T \mid \overline K) P(\overline K)} \\[10pt] &= \frac{P(T \mid K) P(K)}{P(T \mid K) P(K) + (1 - P(\overline T \mid \overline K)) (1 - P(K))} \\[10pt] &= \frac{0.914 \cdot 0.002}{0.914 \cdot 0.002 + (1 - 0.994) \cdot (1 - 0.002)} \\[10pt] &= 0.2339. \end{align}\]
Interpretation
Die Wahrscheinlichkeit, dass eine Person mit positivem Schnelltest tatsächlich krank ist (positiver Vorhersagewert), beträgt also nur rund \(23\%\). Das ist tatsächlich keine sonderlich hohe Wahrscheinlichkeit und auf den ersten Blick verwunderlich, denn sowohl Sensitivität als auch Spezifität liegen als Gütemaße im Beipackzettel des Tests nahe 100%. Auf der folgenden Seite werden wir uns genauer anschauen, warum das so ist.
Quizaufgaben
Einführung Code-Aufgaben
In dieser Lernanwendung werden Ihnen auch Aufgaben gestellt, die Sie mittels R-Code lösen sollen. Dabei geht es um kurze Codeschnipsel, die Sie entweder ergänzen sollen (indem Sie Platzhalter durch entsprechenden Code ersetzen) oder die Sie komplett selbst schreiben sollen. In den meisten Fällen erzeugen Sie dabei ein abschließendes Ergebnis, welches in der letzten Zeile stehen muss.
Beispielaufgabe: Bestimmen Sie den Mittelwert der Augenzahlen eines sechsseitigen Würfels. Im Code haben wir schon die Augenzahlen 1 bis 6 in der Variable wuerfel vorgegeben. Benutzen Sie jetzt eine entsprechende R-Funktion, um den Mittelwert daraus zu bestimmen. Ersetzen Sie dafür den Platzhalter ___.
wuerfel <- 1:6
___(wuerfel)wuerfel <- 1:6
mean(wuerfel)Mit der Funktion mean() lässt sich das arithmetische Mittel in R berechnen.
Wie Sie sehen, müssen Sie also das Endergebnis in die letzte Zeile der Code-Eingabe schreiben.
Aufgabe 1a
Im folgenden Code wird die Konfusionsmatrix konfmat mit den Werten aus dem Beipackzettel erzeugt.
Erweitern Sie den Code so, dass konfmat um die Randsummen erweitert wird. Nutzen Sie dafür die Funktion addmargins.
konfmat <- matrix(c(139, 13, 3, 462), ncol = 2)
colnames(konfmat) <- c("krank", "gesund")
rownames(konfmat) <- c("positiv", "negativ")
konfmatAufgabe 1b
Im folgenden Code wird die Konfusionsmatrix konfmat mit den Werten aus dem Beipackzettel erzeugt. Berechnen Sie \(P(T \mid K) = \frac{P(T, K)}{P(K)}\) direkt mittels konfmat. Sie können auf den Wert in Zeile i und Spalte j zugreifen, indem Sie die Syntax konfmat[i, j] verwenden. Sie können die komplette Zeile i mittels konfmat[i,] und die komplette Spalte j mittels konfmat[,j] auswählen.
konfmat <- matrix(c(139, 13, 3, 462), ncol = 2)
colnames(konfmat) <- c("krank", "gesund")
rownames(konfmat) <- c("positiv", "negativ")
konfmatkonfmat <- matrix(c(139, 13, 3, 462), ncol = 2)
colnames(konfmat) <- c("krank", "gesund")
rownames(konfmat) <- c("positiv", "negativ")
konfmat[1, 1] / sum(konfmat[,1])Wählen Sie mittels konfmat[i,j] den entsprechenden Wert für \(T \cap K\) (positiver Test und krank) aus konfmat aus. Berechnen Sie außerdem die Anzahl der Menschen die nachweislich krank waren als Summe der “krank” Spalte. Das können Sie mittels Auswahl der Spalte machen und der Funktion sum(). Anschließend können Sie die Anzahl für \(T \cap K\) teilen durch die Anzahl für \(K\).
Der Einfluss von Prävalenz und Testgenauigkeit
Schauen wir uns noch mal die Berechnung der bedingten Wahrscheinlichkeit \(P(K \mid T)\) an:
\[\begin{align} P(K \mid T) &= \frac{P(T \mid K) P(K)}{P(T \mid K) P(K) + P(T \mid \overline K) P(\overline K)} \\[10pt] &= \frac{0.914 \cdot 0.002}{0.914 \cdot 0.002 + 0.006 \cdot 0.998} \\[10pt] &= 0.2339. \end{align}\]
Man sieht daran sehr gut, welch großen Einfluss die Prävalenz auf das Gesamtergebnis hat: Selbst bei hoher Sensitivität des Tests wird der Zähler \(P(T \mid K) P(K)\) und damit das Gesamtergebnis sehr klein, wenn die Prävalenz sehr klein ist. Das macht auch intuitiv Sinn: Wenn es insgesamt sehr wenige Fälle einer Krankheit gibt, ist die Wahrscheinlichkeit vergleichsweise gering, dass eine Person ausgerechnet damit erkrankt ist, selbst wenn der Test positiv ausfällt. Dagegen ist die Wahrscheinlichkeit sehr hoch, dass eine Person an einer Krankheit erkrankt ist, bei der es gerade viele Krankheitsfälle gibt (die Prävalenz also sehr hoch ist) ganz unabhängig davon, wie gut der Test funktioniert.
Wir können das auch visualisieren, indem wir \(P(K \mid T)\) in Abhängigkeit der Prävalenz darstellen für fest gewählte Sensitivität und Spezifität:

Wir sehen, wie stark die Kurve ansteigt und schon bei einer Prävalenz von 10% können wir einem Testergebnis mit der gegebenen Sensitivität und Spezifität trauen. Für geringere Prävalenzen ist das weniger gerechtfertigt, wie hier noch mal im Detail dargestellt:
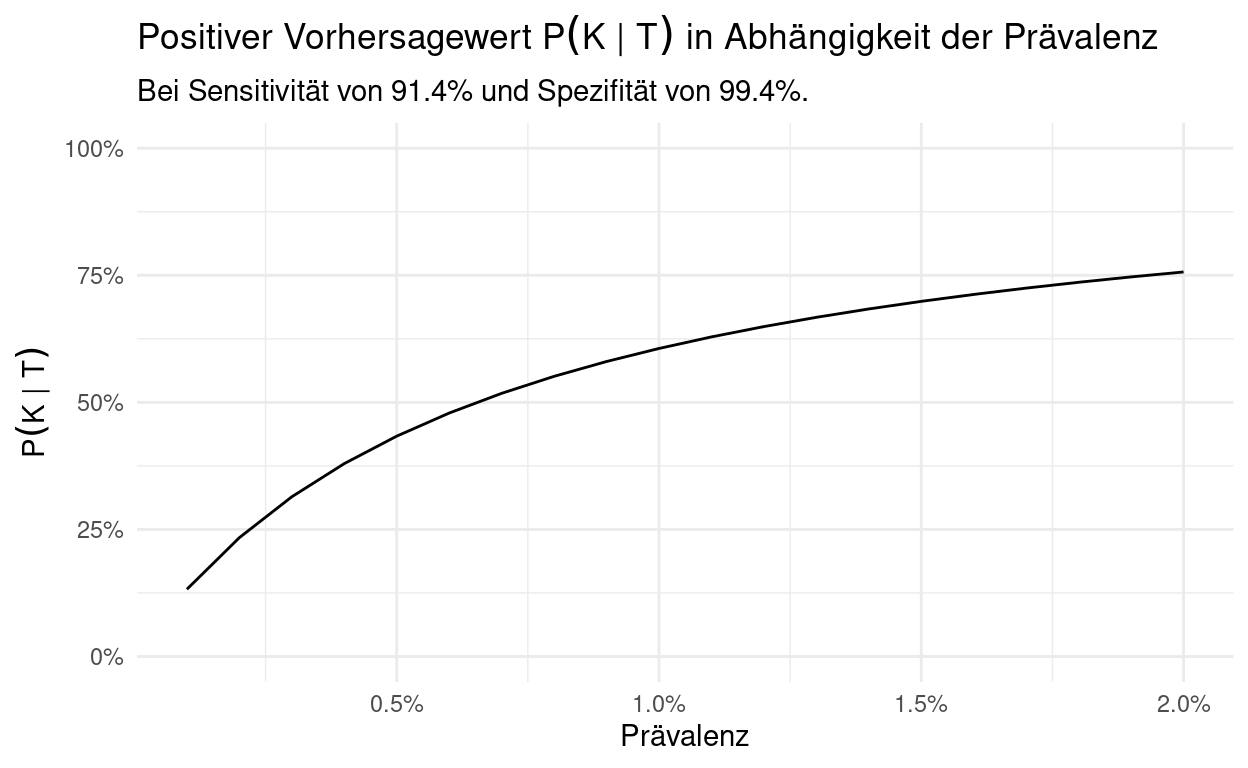
Andererseits zeigt es auch, wie wichtig genaue Tests sind. Bei niedriger Prävalenz spielt hierbei besonders die Spezifität eine wichtige Rolle, wie folgende Grafiken zeigen:
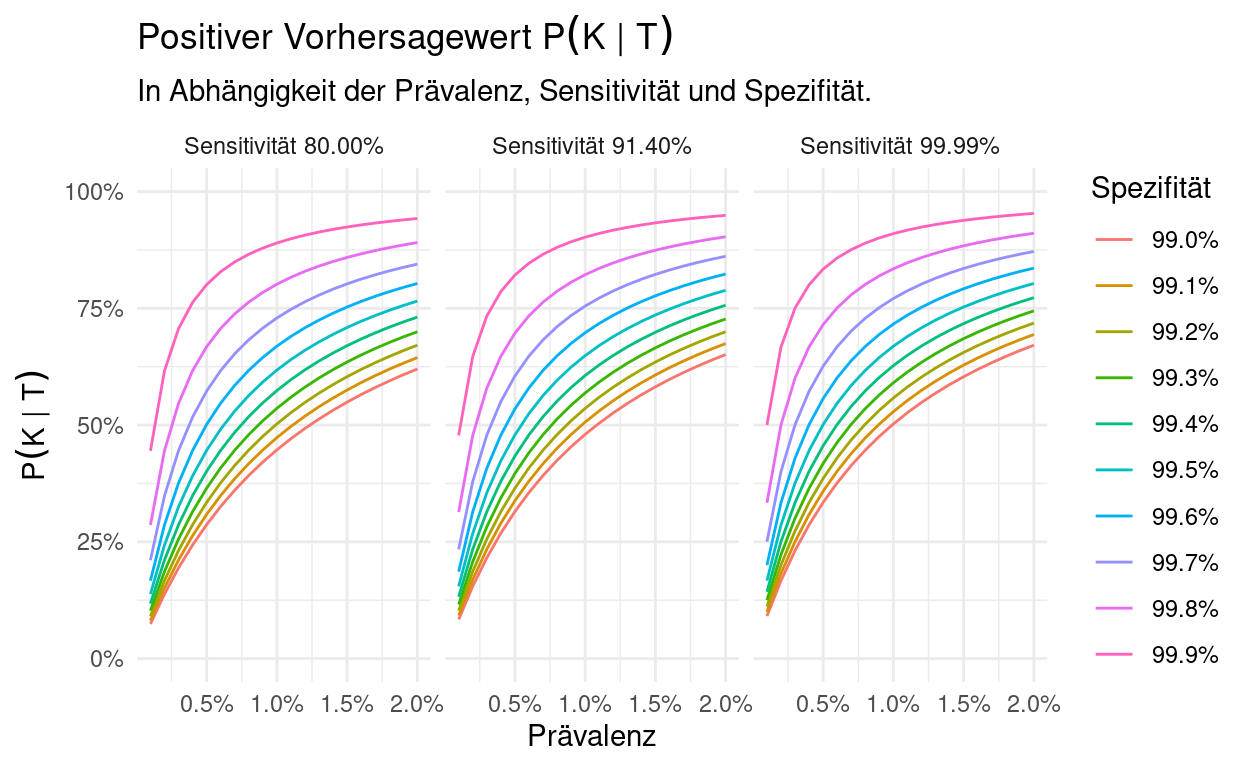
Mittels dieser interaktiven Grafik können Sie für selbst gewählte Sensitivitäts- und Spezifitätswerte den positiven Vorhersagewert in Abhängigkeit zur Prävalenz darstellen:
Die Spezifität \(P(\overline T \mid \overline K)\) hat einen großen Einfluss, denn wie wir schon gezeigt haben gilt
\[\begin{align} P(K \mid T) &= \frac{P(T \mid K) P(K)}{P(T \mid K) P(K) + P(T \mid \overline K) P(\overline K)} \\[10pt] &= \frac{P(T \mid K) P(K)}{P(T \mid K) P(K) + (1 - P(\overline T \mid \overline K)) P(\overline K)}, \end{align}\]
und da \(P(K)\) sehr klein ist, ist \(P(\overline K)\) sehr groß und somit hat die Spezifität \(P(\overline T \mid \overline K)\) über den Term \((1 - P(\overline T \mid \overline K)) P(\overline K)\) die “Macht” über den Nenner. Damit bewirkt eine hohe Spezifität einen kleinen Nenner und damit einen hohen positiven Vorhersagewert.
Wir sehen also: gute Tests (insbesondere mit hoher Spezifität) können hier gerade am Anfang einer Krankheitswelle einen großen Unterschied machen, denn sie erlauben es schon frühzeitig recht zuverlässig Infektionen zu erkennen, selbst wenn die Prävalenz noch niedrig ist.
Auch andere Parameter und Umstände abseits der Prävalenz und der Testgüte haben noch bedeutenden Einfluss auf das Ergebnis. Insbesondere ist es wichtig, wie gründlich der Abstrich vorgenommen wurde. Es ist auch bekannt, dass die Temperatur die Genauigkeit von Covid-Schnelltests beeinflusst. Sie sehen also, dass die Berechnungen noch deutlich komplexer werden können!
Aufgabe 2a
Analog zu den Grafiken für den positiven Vorhersagewert \(P(K \mid T)\) möchten wir eine Grafik für den negativen Vorhersagewert \(P(\overline K \mid \overline T)\) erstellen. Diese Grafik soll den negativen Vorhersagewert in Abhängigkeit von der Prävalenz und der Sensitivität darstellen.
Zunächst brauchen wir dazu einen Dataframe mit einer Reihe von Prävalenz- und Sensitivitätswerten. Erzeugen Sie einen solchen Dataframe für alle Kombinationen aus den Prävalenzwerten \(0.1, 0.2, \dots, 0.9\) und den Sensitivitätswerten \(0.8, 0.91\) und \(0.99\). Sie können dafür die Funktion expand.grid verwenden. Der Dataframe sollte nvw_param heißen und die Spalten praev und sens haben.
nvw_param <- expand.grid(praev = ___,
sens = ___)
nvw_paramnvw_param <- expand.grid(praev = seq(0.1, 0.9, length.out = 9),
sens = c(0.8, 0.91, 0.99))
nvw_paramAufgabe 2b
Berechnen Sie als nächstes den negativen Vorhersagewert \(P(\overline K \mid \overline T)\) für alle gegebenen Parameter und fügen Sie das Ergebnis als Spalte nvw zum Dataframe nvw_param hinzu. Nutzen Sie dafür eine festgelegte Spezifität von \(99.4\%\).
spez <- 0.994
nvw_param$nvw <- ___
nvw_paramspez <- 0.994
nvw_param$nvw <- spez * (1-nvw_param$praev) / (spez * (1-nvw_param$praev) + (1-nvw_param$sens) * nvw_param$praev)
nvw_paramAufgabe 2c
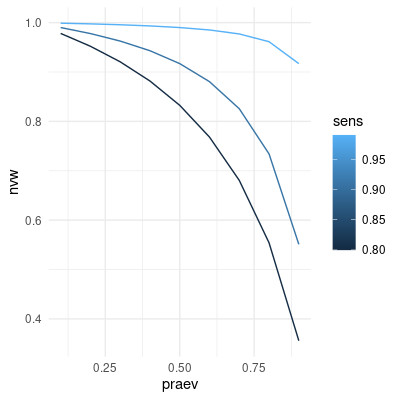
Erstellen Sie eine Grafik mit ggplot2, welche den negativen Vorhersagewert in Abhängigkeit der Prävalenz darstellt. Dabei sollen für die drei unterschiedlichen Werte der Sensitivität drei farblich unterschiedliche Linien dargestellt werden.
Die erzeugte Grafik sollte wie folgt aussehen:
ggplot(nvw_param, aes(___)) +
___ + # "geom_..." für Linienplot
theme_minimal()ggplot(nvw_param, aes(praev, nvw, color = sens, group = sens)) +
geom_line() +
theme_minimal()Datenschutzhinweise
Datenschutzrechtliche Informationspflichten über die Datensammlung im Forschungsprojekt “MultiLA” nach Art. 13 DSGVO
Das Projekt “Multimodale interaktive Lerndashboards mit Learning Analytics” (MultiLA) hat sich zum Ziel gesetzt das Lernverhalten in den zur Verfügung gestellten Lernanwendungen zu erforschen. Zu diesem Zwecke werden Daten erhoben und verarbeiten, worüber wir im folgenden aufklären.
1. Name und Kontaktdaten des Verantwortlichen
Hochschule für Technik und Wirtschaft Berlin
Treskowallee 8
10318 Berlin
T: +49.40.42875-0
Vertreten durch die Präsidentin Praesidentin@HTW-Berlin.de
2. Datenschutzbeauftragter
Behördlicher Datenschutzbeauftragter
Vitali Dick (HiSolutions AG)
datenschutz@htw-berlin.de
Projektverantwortlicher
Andre Beinrucker
andre.beinrucker@htw-berlin.de
3. Die Verarbeitung von personenbezogenen Daten
3.1 Zweck
Die Verarbeitung personenbezogener Daten dient dem Zweck der Analyse des Lernverhaltens und des Umgangs mit interaktiven Lernanwendungen im Rahmen des Foschungsprojekts “MultiLA”.
3.2 Rechtsgrundlage
Die Rechtsgrundlage ist Art. 6 Abs. 1 lit. e DSGVO.
3.3 Dauer der Speicherung
Alle Daten werden nur innerhalb der Lernanwendung aufgezeichnet. Sie werden auf den Servern der HTW-Berlin gespeichert und werden mit Auslaufen des Projektes oder möglichen Folgeprojekten gelöscht.
4. Ihre Rechte
Sie haben das Recht, von der Hochschule Auskunft über die zu Ihrer Person gespeicherten Daten zu erhalten und/oder unrichtig gespeicherte Daten berichtigen zu lassen. Sie haben darüber hinaus das Recht auf Löschung oder auf Einschränkung der Verarbeitung oder ein Widerspruchsrecht gegen die Verarbeitung. Außerdem haben Sie in dem Fall, in dem als Rechtsgrundlage für die Verarbeitung Sie die Einwilligung gegeben haben, das Recht, die Einwilligung jederzeit zu widerrufen. Die Rechtmäßigkeit, der aufgrund der Einwilligung bis zum Widerruf erfolgten Verarbeitung bleibt davon unberührt. Bitte wenden Sie sich in dem Fall jeweils an folgende Person: Andre Beinrucker, andre.beinrucker@htw-berlin.de. Sie haben das Recht auf Beschwerde bei einer Aufsichtsbehörde, wenn Sie der Ansicht sind, dass die Verarbeitung der Sie betreffenden personenbezogenen Daten gegen die Rechtsvorschriften verstößt.
5. Information über Ihr Widerspruchsrecht nach Art . 21 Abs. 1 DSGVO
Sie haben das Recht, aus Gründen, die sich aus Ihrer besonderen Situation ergeben, jederzeit gegen die Verarbeitung Sie betreffender Daten, die aufgrund von Art. 6 Abs. 1 lit. e DSGVO (Datenverarbeitung im öffentlichen Interesse) erfolgt, Widerspruch einzulegen.